In a blog post, penned by Google veterans Jeff Dean and Urs Hlzle, the company announced it has developed and deployed its second-generation Tensor Processing Units (TPUs). The newly hatched TPU is being used to accelerate Googles machine learning work and will also become the basis of a new cloud service.
Hewlett Packard Enterprise has introduced what looks to be the final prototype of The Machine, an HPE research project aimed at developing a memory-driven computing architecture for the era of big data. According to HPE CTO Mark Potter: The architecture we have unveiled can be applied to every computing categoryfrom intelligent edge devices to supercomputers.
Amid all the fireworks around the Volta V100 processor at the GPU Technology Conference (GTC) last week, NVIDIA also devoted a good deal of time to their new cloud offering, the NVIDIA GPU Cloud (NGC). With NGC, along with its new Volta offerings, the company is now poised to play both ends of the cloud market: as a hardware provider and as a platform-as-a service provider.
Riding a wave of excitement for all things AI, NVIDIA has launched the Volta GPU. The revamped architecture sets a new standard for computing performance in HPC, deep learning, and accelerated databases. The new platform was unveiled by NVIDIA CEO Jensen Huang at the GPU Technology Conference (GTC) on Wednesday morning.
As NVIDIAs GPU Technology Conference (GTC) kicks off this week in San Jose, California, vendors are lining up to announce their latest GPU computing wares. Even before the main conference festivities commenced, Supermicro, Inspur, and Boston Limited took the opportunity to launch their new NVIDIA Tesla P100 servers.
Diagnosing disease is one of the more labor-intensive aspects of the healthcare system. It also happens to be one that is particularly well-suited to being performed by machine learning algorithms. While work in this area is in its early stages, the technology is evolving rapidly and appears poised to transform diagnostic medicine.
Silicon Valley startup Wave Computing announced its dataflow compute appliance for machine learning is now available via an early access program, with general availability scheduled for Q4 2017. According to the company, its custom-built appliance can deliver 2.9 petaops of performance and train neural networks an order of magnitude faster than the current crop of GPU-accelerated hardware.
Simon Fraser University (SFU) has officially launched Canadas most powerful academic supercomputer. The new 3.6-petaflop system, known as Cedar, is just the beginning of a big push by the Canadian government to upgrade the network of its 50 aging HPC machines used to serve the nations academic research community.
When a poker-playing AI program developed at Carnegie Mellon university challenged a group of machine learning-savvy engineers and investors in China, the results were the same as when the software went up against professional card players: it beat its human competition like a drum. And that points to AIs greatest strength, as well as its greatest weakness.
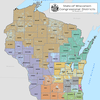
A supercomputing application that can figure out if state legislative districts have been unfairly drawn, has the potential to change electoral politics in the United States. According to its inventors at the University of Illinois at Urbana-Champaign, the application could be used by courts to determine if partisan gerrymandering has been used to unfairly manipulate these maps.