April 23, 2017
By: Michael Feldman
Simon Fraser University (SFU) has officially launched Canada’s most powerful academic supercomputer. The new 3.6-petaflop system, known as “Cedar,” is just the beginning of a big push by the Canadian government to upgrade the network of its 50 aging HPC machines used to serve the nation’s academic research community.
The upgrade, which began last year, will increase the research network’s aggregate performance from 2 to 12 petaflops, while increasing its total storage capacity from 20 to more than 50 petabytes. The effort is being led by Compute Canada, a government organization tasked with deploying these advanced research computing (ARC) systems for the research community.
While Canada’s supercomputing performance is being multiplied six-fold, the number of datacenters housing those systems is being pared down from 27 down to 5 or 10. Four of those facilities will contain the research network’s largest supercomputers, which will form the backbone of the ARC network.
One of these is the new 3.6-petaflop Cedar, which is now running at SFU’s new datacenter located on the Burnaby campus in British Colombia. That system, alone, has more computational horsepower that the entire complement of Canada’s remaining supercomputing network dedicated to the research community. Researchers will use the SFU machine to support a wide array of scientific work, including personalized medicine, green energy technology, and artificial intelligence.
Cedar is a heterogeneous cluster, comprised of Dell server nodes of various flavors, and connected with Intel’s Omni-Path network. All nodes are based on Intel Xeon CPUs of the “Broadwell” persuasion. However most of the Cedar’s performance – 2.744 petaflops, to be exact – comes from GPU accelerators, in this case 584 NVIDIA P100 Tesla GPUs, which are spread across 146 of the system’s 902 nodes.
Other than GPU acceleration, most of the node variation in Cedar has to do with memory capacity, which ranges from 128GB up to a whopping 3 TB. The latter is backed by four E7 Xeon CPUs, representing the only server that doesn’t use a dual-socket E5 Xeon setup.
All Cedar nodes are equipped with local storage. The ones with GPUs have a single 800GB SSD, while the others come with two 480GB SSDs. External storage is provided by DDN gear, specifically the ES14K platform, which in this case comprises 640 8TB SAS drives, backed by SSD-based metadata controllers.
If all goes according to plan, Cedar will soon have company. Next month another petascale supercomputer known as Graham is scheduled to be up and running at the University of Waterloo in Ontario, Canada. Like Cedar, Graham will be a heterogeneous cluster mixing Intel Xeon CPU-only nodes with P100 GPU-accelerated ones. The range of memory capacities in its nodes will be identical to that of its SFU sibling. Unlike Cedar, however, Graham will use InfiniBand as the system interconnect.
Although the Waterloo machine will have about 140 more nodes than Cedar, it will end up being a smaller system, performance-wise, since it will only have 320 of the P100 GPUs. However, those alone are more than enough to earn the system a spot in the petaflop club, but the system’s aggregate peak performance will probably top out at around 2.5 petaflops.
Graham will be constructed by Huawei (Huawei Canada), which will make it the most powerful supercomputer ever built by the company. Huawei’s current top performer is the one installed at the Poznan Supercomputing and Networking Center in Poland. That supercomputer, named HETMAN, delivers 1.37 peak petaflops.
Later this year, a third big system, which will be known as Niagara, is scheduled to be installed at the University of Toronto. It’s anticipated to have approximately 66,000 cores, with no mention of any GPUs. It looks to be just a big vanilla x86 cluster intended for large scaled-out workloads that are not necessarily amenable to manycore acceleration. The vendor has yet to be announced.
The fourth ARC machine is Arbutus, a Lenovo system that was installed last year at the University of Victoria in British Colombia and came online in September 2016. Compared to the other three machines, this is a relatively small cluster, with just 248 nodes and 6,944 cores. The nodes are hooked together with 10GbE, and its main purpose is to host virtual machines and other types of cloud workloads for researchers needing HPC machinery.
The additional computational capacity of these new supercomputers is sorely needed by Canadian scientists. More than 10,000 researchers spread across 70-plus different institutions rely on these systems, and much of the existing hardware is well past its use-by date. There are a number of machines in the current network that are running with ancient AMD Opterons and Nehalem-era Intel Xeons. Some still employ obsolete interconnects like Quadrics and Myrinet.
Last year, Compute Canada performed a study that analyzed computational usage across existing supercomputers for different scientific disciplines. From 2010 through 2013, CPU usage rose dramatically across nearly all research domains. But from 2013 to the end of 2015, usage leveled off as researchers filled the capacity on existing machines. There was even a slight drop in usage toward the end of this period as the oldest systems were decommissioned. The chart below tells the tale, with the Y-axis representing thousands of core-years.
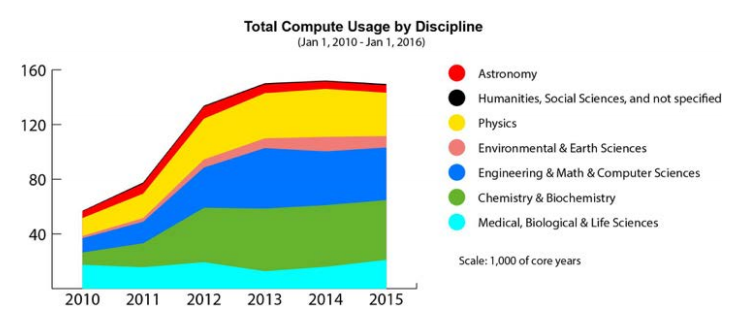 Source: Compute Canada Technology Briefing, November 2016
Source: Compute Canada Technology Briefing, November 2016
The study also found that the many of the older systems were inadequate to run really large-scale jobs, and even the biggest systems, which could handle jobs of this size, had long queue wait times. Analysis showed that for 2016, the existing infrastructure would only be able to meet 54 percent of the requested computational resources and 20 percent of GPU requests.
With the new four system coming online over the next year, this should all change, giving Canadian researchers a lot more breathing room for compute and storage. Beyond that, Compute Canada anticipates a further build-out to provide 20 petaflops of computational capacity and more than 100 petabytes of storage. The timeline for this future upgrade has yet to be determined.