
April 26, 2017
By: Michael Feldman
Silicon Valley startup Wave Computing announced its dataflow compute appliance for machine learning is now available via an early access program, with general availability scheduled for Q4 2017. According to the company, its custom-built appliance can deliver 2.9 petaops of performance and train neural networks an order of magnitude faster than the current crop of GPU-accelerated hardware.
Based in Campbell, California, Wave Computing emerged from stealth mode in July 2016, promising to upend the machine learning market with its patented dataflow architecture. Based on the company’s custom-built Dataflow Processing Unit (DPU), Wave claims they intend to deliver “the world's fastest and most energy efficient computers for the rapidly expanding Deep Learning market.”
The Wave appliance comes in a 3U form factor, which houses 16 DPUs, 2 TB of DDR4 DRAM, 128 GB of high-speed Hybrid Memory Cube (HMC) DRAM, and 16 TB of SSD storage. Up to four appliances can be ganged together into a single 12U “node” using Wave’s proprietary high-speed interconnect.
 Source: Wave Computing
Source: Wave Computing
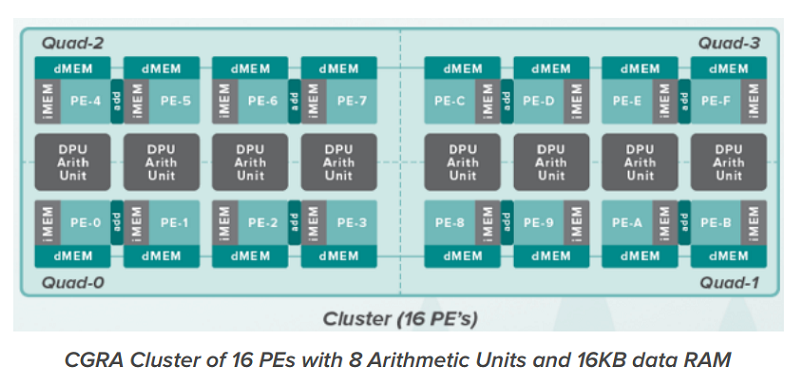
At the heart of all this is the DPU itself, a clock-less chip comprised of 16,384 processing elements (PEs). Wave characterizes it as a coarse-grain reconfigurable array, which looks to be something between an FPGA and an ASIC. By trading off the advantages of both, the company thinks it has found the sweet spot in performance, flexibility, and power efficiency – at least with regards to machine learning.
The chip is not an accelerator since it operates autonomously without the need of a host processor. (The appliance itself employs a CPU for things like program loading, runtime reconfiguration, and checkpointing.) The 16,384 processing elements are arranged in a 32-by-32 array of 16-PE clusters. Each cluster also incorporates 8 DPU arithmetic units. Other on-chip resources include four HMC Gen 2 interfaces, two DDR4 interfaces, and a 16-lane PCIe Gen 3 interface. A 32-bit microcontroller is used to manage these resources.
The DPU arithmetic unit provides 8-bit, 16-bit, and 32-bit operations. Some 64-bit operations are also available, and this can be extended even further via software. Mixed-precision arithmetic is supported, which can be a key strategy to economize on memory storage and bandwidth for machine learning codes. The inclusion of 8-bit operations exists mainly for inferencing, but given the overall design of the DPU and the appliance, these systems seem destined to be used mostly for the more compute-demanding training phase of deep learning.
 Source: Wave Computing
Source: Wave Computing
Since Wave is claiming each 16-DPU appliance provides 2.9 petaops of peak performance, presumably fixed point operations, that means each chip would deliver about 180 teraops. Regardless of whether these are 16-bit or 8 bit operations, or something else, this level of performance appears to be significantly better than other processors currently being employed for machine learning.
NVIDIA’s top-of-the-line P100 GPU, for example, provides 21.2 teraflops at 8 bits and 10.6 teraflops at 16 bits. AMD’s M125 Vega GPU, which is yet another device specifically aimed at neural net training, tops out at 25 teraflops for 16-bit processing. Before Nervana was acquired by Intel, its machine learning ASIC prototype was said to deliver 55 teraops using its 16-bit FlexPoint numeric format. Even the Tensor Processing Unity (TPU), Google’s custom-built ASIC for hyperscale inferencing, attains just 92 teraops with 8-bit integers.
Of course, those are peak performance numbers. Actual application results on real neural networks are going to be something else altogether. Wave has offered a couple of its own examples in this regard. The first used a single appliance to train a deep convolutional neural network (Google Inception v3 model) using 16-bit fixed point computations. The company says it took 15 hours for the training run, which scaled almost linearly to 4.1 hours when four appliances were used. According to Wave, those times outperformed “current GPU-based systems” by a factor of 10. In another case, Wave used a single DPU to train a shallow recurrent neural network (Word2Vec model). Using a mix of 16-bit, 32-bit and 64-bit fixed point math, the DPU was able to train the network in 6.75 seconds, which was more than 500 times faster than three different four-CPU systems, one which had a K80 GPU accelerator to draw on.
Despite the custom nature of the DPU and system design, Wave says conventional software tools can be used for application development. The company provides its own WaveFlow SDK, which includes the typical compile-linker-simulator-debugger toolchain. The compiler is the key piece, taking standard C/C++ code and turning it into a dataflow graph that can be mapped onto the DPUs. A WaveFlow Agent Library and Execution Engine are provided for runtime support. The software stack will initially support the TensorFlow deep learning framework, but plans to add Microsoft’s Cognitive Toolkit (CNTK), MXNet, and others are already in the works.
Whether all of this is enough to overtake NVIDIA, Intel, and other companies developing purpose-built hardware for machine learning remains to be seen. Nevertheless, Wave’s dataflow appliance should pique the interest of data scientists and AI developers looking to latch onto the next big thing. The company is offering its early access program for anyone interested in kicking the tires prior to its general release in the fourth quarter of the year. Pricing has yet to be announced, but given all the high-end hardware and customized design, this dataflow box is not going to come cheap.