July 21, 2016
By: Michael Feldman
Silicon Valley's newest chipmaker, Wave Computing, came out of stealth mode this week, announcing a family of computers purpose-built for deep learning. The new systems are powered by the Wave Dataflow Processing Unit (DPU), a massively parallel dataflow processor designed to optimize the learning models. According to the company, the technology performs an order of magnitude faster than GPUs or FPGAs and is more energy efficient.
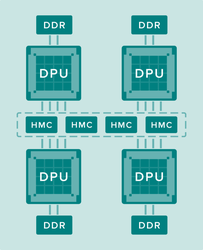
The technical details of the DPU are a bit sketchy. Besides the fact that it’s a dataflow architecture, Wave revealed that the hardware includes built-in support for popular machine learning frameworks, such as Google’s TensorFlow and Microsoft’s CNTK. In addition, the processor will utilize both DDR memory and Hybrid Memory Cube (HMC), the high-bandwidth 3D memory developed by Micron. For a deeper look at the architecture, Wave says it plans to disclose the nitty-gritty of the DPU design at the Linley Processor Conference next month.
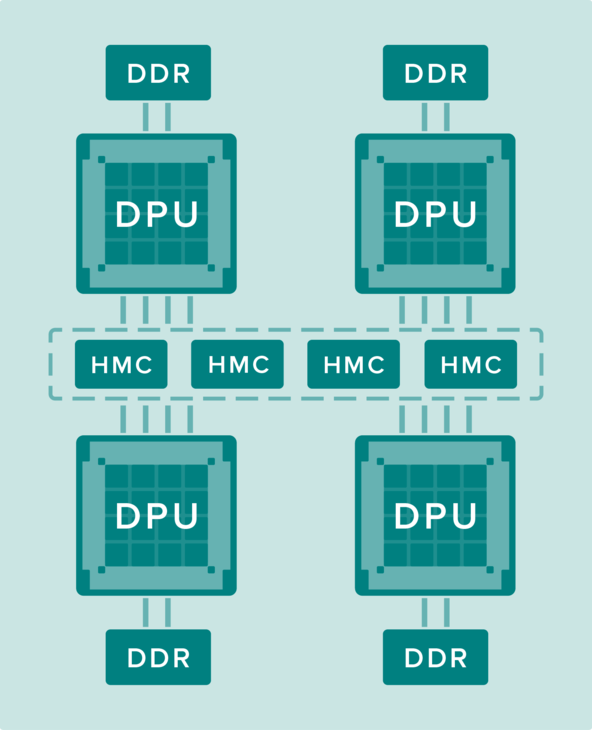
Image: Wave Computing
The use of HMC is an important aspect of the system design, since it will be used to deliver bits and bytes to the data-hungry deep learning applications at rates much higher than can be achieved with the conventional memory. It’s worth noting that two other major platforms for deep learning, NVIDIA’s Tesla P100 and Intel’s Knights Landing Xeon Phi, also use 3D memory: in the case of the P100, the second-generation High Bandwidth Memory (HBM2), and in the case of Knights Landing, the second-generation HMC. As it turns out, both sets of 3D solutions may end up playing a big part in deep learning, a market that, ironically, was not envisioned when development of these memory technologies began more than five years ago.
As part of the announcement, Wave Computing CEO Derek Meyer said their systems can be used for both inference and training. The latter is the most computationally demanding part of deep learning, the one which GPUs, FPGAs, and now Xeon Phi processors are particular good at. Google has its own custom-built processor for deep learning, which it calls the Tensor Processing Unit (TPU), but that chip appears to be better suited to inference applications.
If Wave’s technology proves to be an order of magnitude better at training the models than GPUs and their ilk, and if it can do so for roughly the same cost, NVIDIA’s and Intel’s strategy to expand into this market with their more generic offerings could be compromised. That a couple of big ifs. In general, developing custom-built chips for specific application sets is economically challenging, even under the best of circumstances. Right now the volumes of processors devoted to deep learning, especially with regard to the training component, probably don’t warrant a custom approach. But if the market grows, the ROI becomes more and more attractive.
If the deep learning market does expand to the point where custom approaches make sense, Wave would be a good position to capitalize. In fact, if the technology proves out, the company would most likely be bought by either one of the big users of deep learning, namely the web service and content providers, or one of the major chipmakers or OEMs.
In the meantime, Wave says it is currently working with system developers to provide the first DPU-powered machines for later this year. These initial systems will be available for “Early Access” customers only. General availability is scheduled for 2017