
May 11, 2017
By: Michael Feldman
Riding a wave of excitement for all things AI, NVIDIA has launched the Volta GPU. The revamped architecture sets a new standard for computing performance in HPC, deep learning, and accelerated databases. The new platform was unveiled by NVIDIA CEO Jensen Huang at the GPU Technology Conference (GTC) on Wednesday morning.

Source: NVIDIA
The initial Volta product will be the Tesla V100, NVIDIA’s high-end accelerator designed for datacenter duty. It comprises 21.1 billion transistors and is built using TSMC’s 12nm FinFET technology. The top-end 300-watt chip delivers 7.5 teraflops of double precision floating point (FP64) performance and 15 teraflops at single precession (FP32). That represents a 50 percent performance bump compared to the existing P100 Tesla GPU. The V100 also provides 120 teraflops of “deep learning” performance, courtesy of 640 Tensor Cores designed specifically to accelerate processing of neural networks. More about this feature later.
NVLink, NVIDIA’s custom inter-processor interconnect, has been upgraded to 300 GB/second, nearly doubling the 160 GB/second data rate of the original NVLink featured in the P100 Tesla GPU. It does this by increasing the number of links from four to six, and upping the data rate per link to 25 GB/second. The new interconnect will be especially valuable to future IBM customers, since the upgraded NVLink will supports CPU mastering and cache coherence, capabilities which will be exploited by IBM’s upcoming Power 9 processor.
Perhaps the least impressive component in the V100 is its 3D memory, the High Bandwidth Memory (HBM2) module integrated into the package. Using the latest parts supplied by Samsung, bandwidth for the 16GB HBM2 module improved only modestly -- from 732 GB/second on the P100, to 900 GB/sec on the V100. NVIDIA did, however, include a new memory controller in Volta, which they say bumps up usable bandwidth by 50 percent. That at least keeps pace with the 50 percent increase in raw floating point performance. A detailed comparison of the V100 with the P100 and previous Tesla GPUs is provided below.
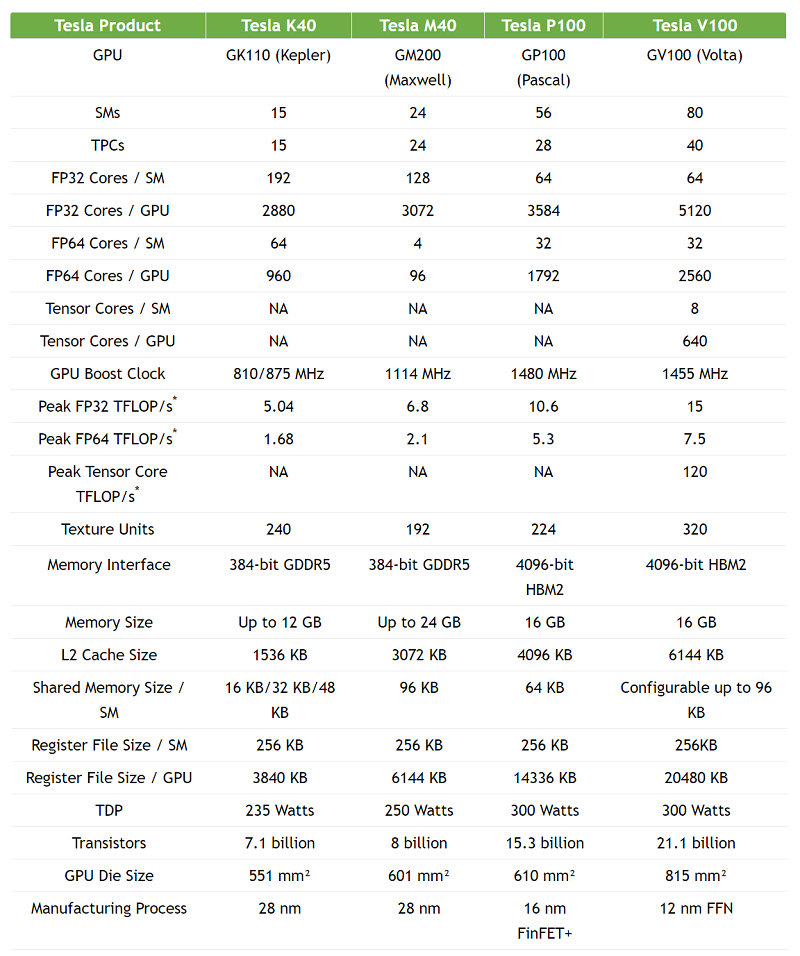
Source: NVIDIA
The 300-watt Tesla V100 is aimed at supercomputers and modest sized clusters or appliances dedicated to training neural networks, HPC, and database acceleration. The general idea here is to maximize performance per server. You can do deep learning inferencing with this top-end part as well, but it typically won’t be used this way since NVIDIA will also offer a 150-watt version that fits better with the type of infrastructure used for this task.
NVIDIA says the 150-watt Tesla V100 delivers 80 percent of the performance of the 300-watt part. It uses the exact same GPU; just the clock frequency has been trimmed to provide better energy efficiency. The audience here is cloud service providers, who want a lower-power part that can be mass deployed across a hyperscale datacenter for either neural network inferencing or training (or both). 150 watts is pretty much the upper limit for an accelerator in a hyperscale environment, but NVIDIA engineers here at GTC suggested that the wattage can be dialed down further for customers with more constrained power requirements.
Although NVIDIA didn’t talk up the low-power V100 for high performance computing, there’s no reason why it couldn’t be used for such work. Certainly, for power-constrained HPC datacenters, a 50 percent power reduction for 80 percent of the performance would appear to be an attractive tradeoff, especially when you consider that for 150 watts you can have a GPU that is marginally faster than today’s speediest 250-watt P100. Depending upon how NVIDIA prices the low-power V100, it could end up being a rather popular accelerator for traditional HPC.
Architectural enhancements in Volta are abundant and wide-ranging. The most important is the addition of the aforementioned Tensor Cores, which provide 120 Tensor teraflops for either training and inferencing neural networks. That’s 12 times faster than the P100 for FP32 operations used for training and 6 times faster than the P100 for FP16 used for inferencing.
In a nutshell, the Tensor Cores provide matrix processing operations that align well with both deep learning training and inferencing, which involves multiplying large matrices of data and weights associated with neural networks. More specifically, each of the 640 Tensor Cores does mixed precision floating point operations on a 4x4x4 array. In a single clock cycle, each core can do 64 FMA (fused multiply-add) operations. Each FMA multiplies two FP16 matrices and adds a FP16 or FP32 matrix, with the result stored in a FP16 or FP32 matrix.
Other Volta upgrades include a much faster L1 cache, a streamlined instruction set for quicker decoding and reduced latencies, FP32 and INT32 units that can now operate in parallel, and FMA operations that can be executed in four clock cycles instead of the six required in the Pascal architecture. Volta also supports independent thread scheduling, which will allow developers to be more creative with their code and enable much fine-grained parallelism. A deeper dive into all these features can be seen on NVIDIA’s Volta webpage.
The first Tesla V100 parts will be available in Q3 of 2017. Amazon has already committed to creating new instances with the new GPUs as soon as they can purchase them in quantity. The Department of Energy also has dibs on some of the earliest units, since they are the accelerator that will be powering the agency’s Summit and Sierra supercomputers. Both systems are expected to begin construction before the end of the year. Other early customers of the V100 include Baidu, Facebook, Microsoft, and Tencent.