A report this week in the New York Times describes how the growing demand for AI is forcing big web companies to ratchet up salaries in this red-hot job category and sucking up all available talent. But the technology itself may provide the final solution.
In an editorial posted on Intels news site, Intel CEO Brian Krzanich announced they would be releasing the companys first AI processor before the end of 2017. The new chip, formally codenamed Lake Crest, will be officially known as the Nervana Neural Network Processor, or NNP, for short.
Over the last several years, the realm of high performance computing has grown appreciably beyond its roots in scientific simulations. Today it encompasses a lot more data analytics, including emerging areas like artificial intelligence, as well as more established applications like business intelligence. But, if youre an HPC market research company like Hyperion Research, tracking the high-end analytics space is no easy task.
Chinese researchers have developed a method to measure the intelligence quotient (IQ) of AI applications and found that Googles technology scored nearly as well as a human six-year old. The researchers also measured applications developed by Baidu, Microsoft and Apple, all of which fared less well.
The US Department of Energy is in the process of revamping the contract for the Aurora supercomputer, shifting its deployment from 2018 to 2021, and increasing its performance from 180 petaflops to over 1 exaflop. That will more than likely make it the first supercomputer in the US to leap over the exascale hurdle.
The worlds largest server OEMs announced they will be soon be shipping systems equipped with NVIDIAs latest Volta-generation V100 GPU accelerator. Included in this group are Hewlett Packard Enterprise (HPE), Dell EMC, IBM, Supermicro, Lenovo, Huawei, and Inspur, all of which took the opportunity to reveal their Volta-powered servers at this weeks GPU Technology Conference in China.
Intel Labs has developed a neuromorphic processor that researchers there believe can perform machine learning faster and more efficiently than that of conventional architectures like GPUs or CPUs. The new chip, codenamed Loihi, has been six years in the making.
Moores Law, the engine that has driven the electronics industry for the past 50 years, is running on fumes. But DARPA, the US Defense Advanced Project Agency, is looking to refill the gas tank with new research initiatives, backed by a $216 million investment.
Hyperion Research says 2016 was a banner year for sales of HPC servers. According to the analyst firm, HPC system sales reached $11.2 billion for the year, and is expected to grow more than 6 percent annually over the next five years. But it is the emerging sub-segment of artificial intelligence that will provide the highest growth rates during this period.
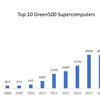
Over the last year, the greenest supercomputers in the world more than doubled their energy efficiency the biggest jump since the Green500 started ranking these systems more than a decade ago. If such a pace can be maintained, exascale supercomputers operating at less than 20 MW will be possible in as little as two years. But thats a big if.