Sept. 5, 2017
By: Michael Feldman
Over the last year, the greenest supercomputers in the world more than doubled their energy efficiency – the biggest jump since the Green500 started ranking these systems more than a decade ago. If such a pace can be maintained, exascale supercomputers operating at less than 20 MW will be possible in as little as two years. But that’s a big if.
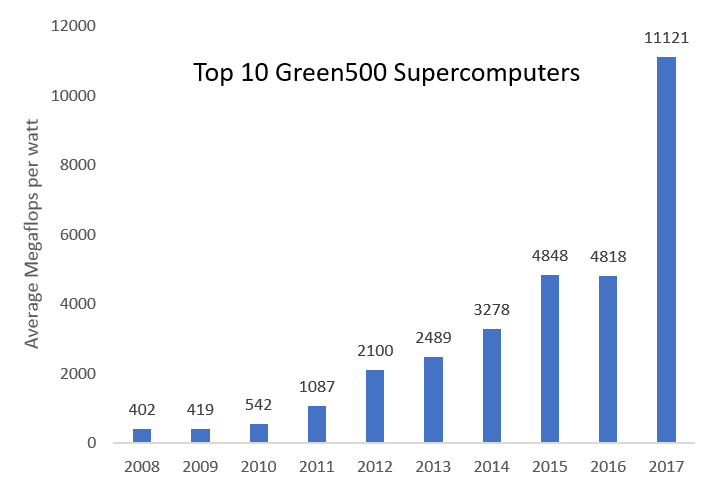
The chart above illustrates the progression of the top-ranked Green500 supercomputers over the last 10 years. From June 2016 to June 2017, the average energy efficiency of the top 10 systems leapt from 4.8 gigaflops per watt to 11.1 gigaflops per watt, representing a 2.3x increase in just 12 months. That jump was mainly the result of the deployment of supercomputers equipped with NVIDIA’s Tesla P100 GPUs, which were present in 9 of those top 10 machines. Those Pascal GPUs, themselves, nearly doubled the energy efficiency of the previous generation Kepler graphics processors launched in 2014.
It’s worth noting that those 10 top systems are not green stunt machines. They are being used for production HPC, namely traditional simulation and modeling, deep learning, or both. Six are bona fide petascale supercomputers, having achieved a petaflop or better on the High Performance Linpack (HPL) benchmark used for TOP500 rankings. They include Piz Daint, a 19.6-petaflop system deployed at the Swiss National Supercomputer Center, Tokyo Tech’s 2.0-petaflop TSUBAME 3.0, and a 3.3-petaflop DGX Saturn V machine deployed at Facebook. TSUBAME 3.0, by the way, is the current Green500 champ, with an energy efficiency rating of 14.1 gigaflops/watt. That’s nearly a third of the way toward the 50 gigaflops/watt needed to field a 20 MW exascale supercomputer.
The fact that the majority of these top machines are based on commodity parts means that these technologies can be broadly applied across the HPC spectrum, from capability-class supercomputers to small and mid-sized clusters. That was not the situation in years past. The last big leap forward in performance-per-watt at the top of the Green500 list came between 2010 and 2012, when the highly customized IBM PowerXCell 8i-based clusters and Blue Gene/Q supercomputers were making their way into HPC datacenters. During this two-year period, efficiencies nearly doubled annually thanks to the superior efficiencies of these non-commodity chips compared to their x86 brethren.
Which brings us back to the P100, which itself was something of an anomaly, inasmuch as it represented a two-generation upgrade from the Kepler-era GPUs. For the most part, NVIDIA skipped Maxwell Tesla products, going directly from the K20/K40/K80 parts to the P100. The detour around Maxell may help to explain the flattening of the Green500 energy efficiency curve between 2015 and 2016. The appearance of the Pascal chips in 2016 resulted in the aforementioned doubling of GPU energy efficiency, from 9.7 gigaflops/watt for the K80 to 17.6 gigaflops/watt for the P100.
That kind of increase may be difficult to reproduce. The new V100 – the 250-watt PCIe version, not the 300-watt NVLink version – can achieve 28 gigaflops/watt, which represents approximately a 60 percent increase in peak efficiency compared to the P100s. While that’s respectable, it’s significantly less than the 80 percent jump from Kepler to Pascal.
However, when NVIDIA launched the V100, the company announced it would also be offering a 150-watt V100 for cloud datacenters, aimed mainly at deep learning workloads. That product is supposed to offer 80 percent of the performance of the top-of-the line NVLink-based part, which would give it a peak performance of 6 double precision teraflops. Theoretically, at least, that would mean the 150-watt variant could deliver 40 gigaflops/watt, which would more than double the P100 mark.
As encouraging as that sounds, most supercomputer buyers are still more driven by performance than performance per watt. For cost considerations, they prefer to maximize performance in a node, rather than spreading the same performance out across more nodes. Given that, the more energy efficient V100 will, as intended, will probably find its main audience with cloud providers, where power costs and datacenter constraints make the use of 200-plus-watt processors problematic.
Beyond GPU coprocessors, Intel’s manycore Xeon Phi offers another viable path to energy efficient supercomputing based on commodity parts. On the latest Green500 list, there are 13 systems powered by the standalone “Knights Landing” Xeon Phi processors. The most energy efficient of these is QPACE 3, deployed at Fujitsu Collaborative Research Center, in Germany. It turned in a result of 5.8 gigaflops/watt, which earned it the number 18 spot on the current list.
While that’s only about 40 percent as efficient as the P100-powered TSUBAME 3.0, future iterations of the Xeon Phi, such as the future Knights Hill processors, are likely to be significantly more energy-efficient. Whether they are able to catch up to the NVIDIA GPUs in this regard, remains to be seen.
Other possible platforms for green supercomputing include the ARM processor, both the standard ARMv8-A design and the variant with Scalable Vector Extension (SVE) capabilities that Fujitsu is developing for its first exascale delivery. China is also interested in ARM, as well as its domestic ShenWei processor as possible chips for its future exascale supercomputers. The National University of Defense Technology (NUDT) is also looking to incorporate the Matrix2000 GPDSP accelerator into its pre-exascale Tianhe-2A machine later this year. None of these chips are likely to be commonplace anytime soon, but each could help push the energy efficiency curve toward the coveted 50 gigaflops/watt territory.
All of which makes for interesting times for HPC architectures. Gone are the days when Moore’s Law and its transistor-shrinking magic could be counted on to deliver all the requisite increases in performance and performance per watt. For the foreseeable future, it’s going to be up to chip designers and systems architects to build supercomputers that are as efficient as they are powerful.