
May 24, 2018
By: Michael Feldman
At Intel’s inaugural AI DevCon conference this week, AI Products Group chief Naveen Rao updated their roadmap for its artificial intelligence chips. The changes will impact the much-anticipated Neural Network Processor, and to a lesser degree, its general-purpose products like Xeons and FPGAs.
Naveen Rao presenting Lake Crest processor at AI DevCon. Source: video screen capture
During the conference’s opening keynote, Rao began by noting that most machine learning currently runs on Xeon processors, and does so with respectable performance. “You may have heard that GPUs are 100x faster than CPUs,” he told his developer audience. That’s simply false.”
The wide use of Xeon processors for these applications stems from the fact that the largest volume of machine learning computation, by far, is on the inferencing side, not the training side. Training is done once to build a model, while inferencing is performed innumerable times to query it. General-purpose CPUs like Xeon processors do inferencing reasonably effectively since it tends to be less computationally demanding than training and is more concerned with delivering a response in a reasonable of time to users.
To make those Xeon processors even more attractive for this work, Intel has added instructions in the latest Skylake processors that speed up neural network processing. In addition, the company has added software support and optimizations for these types of workloads, which have also increased performance. That work is ongoing.
Facebook’s head of AI infrastructure, Kim Hazelwood, was brought out on stage to bolster that argument. She told the audience that the company currently runs a large segment of its inferencing work in areas like speech recognition, language translation and news ranking using regular CPU-powered servers. The main reason for this is that Facebook has a lot of different types of applications to support and using general-purpose hardware for all of them across its vast datacenter empire is just easier-- and presumably less expensive. “Flexibility is really essential in this type of environment,” said Hazelwood. What was left unsaid is that Facebook uses NVIDIA GPUs to do much of their offline AI training work.
In some cases though, CPUs are more attractive for training since the datasets are so large that the more limited local memory available on a GPU accelerator becomes too limiting. Right now, the largest local memory configuration for an NVIDIA V100 GPU is 32 GB.
Apparently, this was the critical factor for Novartis, which is using use Xeon Skylake gear to train image recognition models being used for drug screening. The images in question were so large and numerous that the model used 64 GB of memory – a third of the server’s memory capacity – for this particular application. Moving from a single node to an eight-node cluster, Novartis was able to reduce training times from 11 hours to 31 minutes.
Having said all that, Rao said they are primarily positioning the Xeon platform for environments that mix training with other workloads or for dedicated setups for large-scale inferencing. The latter use case appears to overlap Intel’s positioning of its FPGA products, but at this point Intel certainly realizes that most inferencing deployments are going to be CPU-based. Microsoft is the notable exception here, having already deployed Intel FPGAS at cloud scale on its Azure infrastructure for AI inferencing and a handful of other workloads.
Here, it's worth noting that Rao never brought up Knights Mill, the Xeon Phi variant built for machine learning. Three SKUs of the product were quitely launched in the fourth quarter of 2017 and are still listed on Intel's website, but their ommision here suggests Intel has given up on using Xeon Phi as a vehicle for this market, and, as we've suggested before has likely has given up on Xeon Phi altogether.
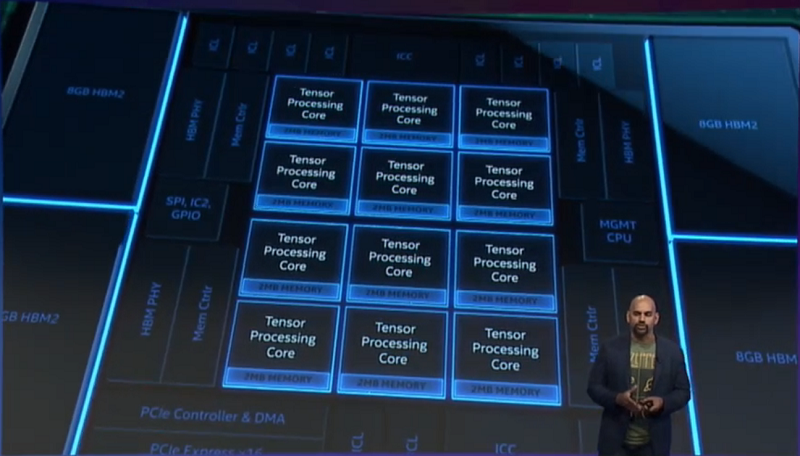
Which brings us to Lake Crest, Intel’s first-generation Neural Network Processor (NNP) custom-built for training neural networks. Based on technology Intel acquired in the 2016 Nervana acquisition, Lake Crest was supposed to debut last year, but for whatever reason, is only now seeing the light of day. The chip is equipped with 12 cores, each of which have two deep learning math units. The device also contains 24 MB of local memory – 2 MB per core – backed by 32 GB of on-package high bandwidth memory (HBM2).
Lake Crest devices can be connected via an I/O link that delivers up to 2.4 terabits/second at less than 790 nanoseconds of latency. This high-speed communication link fulfills one of Intel’s primary goals for this platform, namely that a high level of parallelism can be supported using multiple NNP processors.
The other principle design goal for the NNP platform is to provide high utilization of the available computational power. According to Rao, Lake Crest will deliver approximately 40 peak teraflops of deep learning performance, which is a good deal less than the 125 teraflops of its principle rival, NVIDIA’s V100 GPU. But Rao’s contention is that Lake Crest achieves a much better yield of its available flops than that of the V100 GPU. We should point out here that Rao actually never mentioned NVIDIA or the V100 explicitly, referring to the competing platform as “Chip X.”
During his keynote, he threw up a chart comparing utilization rates that illustrated the semi-fictional Chip X could only deliver 27 teraflops on General Matrix-Matrix Multiplication (GEMM), a key operation common to many deep learning algorithms. On this same benchmark, Lake Crest was able to achieve 38 teraflops, which represents a 96 percent yield of available flops. Rao also noted that Lake Crest achieves nearly the same GEMM yield on two connected chips versus a single NPP. Whether that scales up to even larger number of processors – say eight or more – remains to be seen.
Of course, machine learning codes encompass a lot more than GEMM operations, so utilization rates are going to vary from application to application. (And we’re sure NVIDIA will have something to say about this.) But it’s certainly plausible that a custom-built machine learning chip would be more efficient at these types of codes than a more general-purpose processor like a GPU.
Lake Crest draws less than 210 watts, which compares to 300 watts for an NVLink V100 and 250 watts for the PCIe version. That will make these chips marginally easier to squeeze into datacenter servers than their more power-demanding GPU competition.
But apparently Lake Crest will never get the chance. The product won’t be generally available since Intel only intends to release it in limited quantities as a “Software Development Vehicle.” Rao says the first broadly available NNP processor will be Spring Crest, whose product designation is NNP-L1000. It's scheduled for general release in late 2019 and is anticipated to be three to four times faster than Lake Crest. That should put it in the range of 120 to 160 peak teraflops per chip.
Spring Crest will also include support for bfloat16, a numerical format that essentially squeezes a standard 32-bit floating value into a 16-bit float customized for tensor operations. It uses the same 8 bits for the exponent as a standard 32-bit float but allocates only 7 bits for the mantissa, which the AI gods have deemed to be enough for deep learning computation. The more compact format means bandwidth can be effectively doubled as data is shuttled around the system. It also enables chip architects to design smaller multiply units, which means more of them will fit onto a die.
Intel, Google, and perhaps others, are hoping bfloat16 becomes a standard numerical format for processing neural network. Over time, Intel plans to support this format across all their AI products, including the Xeon and FPGA lines.
Rao wrapped up the hardware roadmap portion of his presentation by revealing that Intel is working on a discrete accelerator for inferencing, the idea being to achieve the best possible performance per watt for. The AI chief wasn’t able to share any details of the future chip, not even its code name. “Look for announcements coming up soon,” he said.