
Aug. 22, 2018
By: Michael Feldman
Fujitsu has announced the specifications for A64FX, an Arm CPU that will power Japan’s first exascale supercomputer. The system, known as Post-K, is scheduled to begin operation in 2021.
 The announcement took place at the Hot Chips conference that was held in Silicon Valley earlier this week.
The announcement took place at the Hot Chips conference that was held in Silicon Valley earlier this week.
The A64FX is made up of 8,786 million transistors and will be manufactured with 7nm process technology. It will be the first CPU to implement Arm’s Scalable Vector Extension (SVE), an instruction set designed specifically for high performance computing.
As we reported in June, Fujitsu has already produced a prototype of the processor and had begun its initial testing. In conjunction with that announcement, the company revealed some of the basic details of the CPU, including its core count (48 compute cores plus 4 assistant cores) and the SIMD vector width (512 bits). At the Hot Chips event, Fujitsu’s Toshio Yoshida provided a much deeper dive into the microarchitecture and its performance profile.
As the first SVE Arm chip, the A64FX has put up some decent floating point performance numbers: over 2.7 teraflops for 64-bit (FP64) operations, over 5.4 teraflops for 32-bit (FP32) operations, and over 10.8 teraflops for 16-bit (FP16) operations. The latter two are especially important for deep learning applications, which traditionally use the lower precision FP32 and FP16 for training neural networks.
The A64X also has implemented integer dot product operations for 16-bit (INT16) and 8-bit (INT8) formats, which can be used for inferencing those same networks. Fujitsu says the new CPU can achieve more than 21.6 teraops using INT8 and more than 10.8 teraops for INT16.
Although floating point performance is certainly respectable, its only about 35 percent faster than the top-of-the-line Xeon Skylake CPUs and more than 20 percent slower than the now-defunct Xeon Phi CPUs. It’s not hard to imagine that Intel will be producing floppier CPUs in the same 2021 timeframe for its Aurora exascale supercomputer, either with the Ice Lake Xeon CPUs or the unconfirmed Xeon AP processors. On the other hand, by providing only low-end performance estimates for the A64FX, Fujitsu may be hinting that it will boost those numbers by the time the final silicon rolls out in a couple of years.
Flops aren’t everything, but they do give us some idea of the number of processors that will be required for an exascale machine. Using the conservative 2.7 teraflops/chip estimate, it will take more than 370 thousand of these chips to get to a peak exaflop and probably more like 400 thousand to achieve an exaflop on Linpack or on a really floating-point-intensive application.
Since Fujitsu is planning to put just a single A64FX in each Post-K node, that 400 thousand number also translates to the node count. Given that Post-K will have 384 nodes per rack, the system would need more than 1,000 such racks in the final exascale machine. Again, Fujitsu could improve the peak flops if it continues to refine the chip over the next two years.
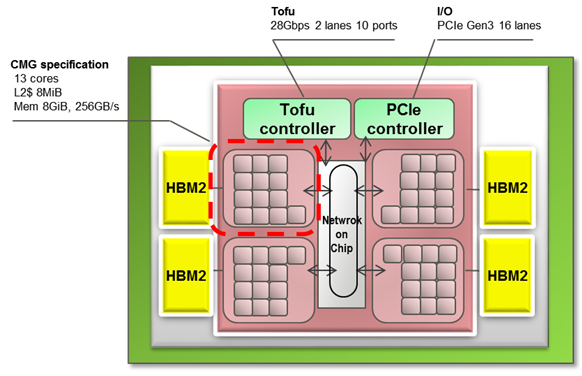
Regardless, the large number of nodes points to the need for a high-performance interconnect. For that, the A64FX will be equipped with an on-chip network controller that will route data over the system’s Tofu fabric. For Post-K, this fabric will be a 6D mesh/torus with each processor providing 2 lanes, each with 10 ports at 28 Gbps. That works out to 560 Gbps per CPU or node.
Another standout is memory bandwidth. In this regard, the A64FX will deliver up to 1024 GB/second per CPU using 32GB of on-package HBM2 memory. According to Fujitsu, they are able to achieve over 830 GB/second on the Stream Triad benchmark, a yield of over 80 percent of the processor’s peak bandwidth. Fujitsu made no mention of connecting this chip to conventional DDR memory.
Internally, the 48+4 cores are divided into four Core Memory Groups, or CMGs. A CME is 13 cores, which consists of 12 compute core and one assistant core. The latter handles OS functions like I/O and daemon processing. Each of the 13 cores is equipped with 64 KB of L1 cache, which can transfer data at more than 11 TB/second.
Each CMG comes with 8MB of L2 cache, which operates at over 3.6 TB/second. The L2 cache is hooked into a memory controller and an interface to the network-on-chip (NoC). The NoC talks to the other CMGs, as well as the Tofu and PCIe controllers.
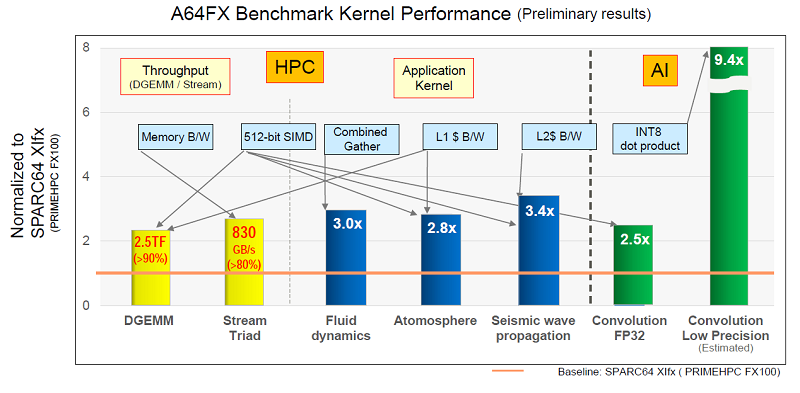
On average, the A64FX is about 2.5 times faster than the SPARC64 XIfx, the company previous high performance CPU, across a range of HPC and AI workloads. The processor is particularly fast in areas like fluid dynamics and seismic wave propagation, where it recorded a 3.0x and 3.4x speedup, respectively.
On the software front, Fujitsu and RIKEN, the customer for the Post-K machine, are co-developing software for both the A64FX processor and the system itself. Linaro, a developer of Arm-based system software and tools, as well as various open source and ISV developers, will also be contributing. By the time 2021 rolls around, expect to see a full stack of HPC software components, including Linux, C/C++ and Fortran compilers, debuggers, MPI, OpenMP, math libraries, resource managers, and Lustre, among others.
All images courtesy of Fujitsu