March 14, 2018
By: Michael Feldman
After just three years in the field, the High Performance Gradients (HPCG) benchmark is emerging as the first viable new metric for the high performance computing crowd in decades. The latest HPCG list compiled last November shows 115 supercomputer entries spread across 16 countries.
![]() In supercomputing circles, High Performance Linpack (HPL) has been the de facto benchmark for HPC systems for the last quarter of a century. Based on a dense system for linear equations, HPL is used to rank supercomputer performance on the 25-year-old TOP500 list and is often used as a burn-in test for newly installed HPC machinery.
In supercomputing circles, High Performance Linpack (HPL) has been the de facto benchmark for HPC systems for the last quarter of a century. Based on a dense system for linear equations, HPL is used to rank supercomputer performance on the 25-year-old TOP500 list and is often used as a burn-in test for newly installed HPC machinery.
At best though, HPL is only a relative indicator of how well your science or engineering application is likely to do on a given machine. Unless your application spends an inordinate amount of time factoring and multiplying dense matrices of floating point numbers, you’re unlikely to get anything close to the performance reflected by Linpack results.
Mike Heroux, the creator and original developer of HPCG, along with Jack Dongarra and Piotr Luszczek, have been championing their alternative metric since they started collecting submissions in 2014. In a recent news release from Sandia National Laboratories that spotlights the newfound prominence of the benchmark, Heroux pointed to the shifting profile of HPC applications as an impetus for running HPCG:
“The Linpack program used to represent a broad spectrum of the core computations that needed to be performed, but things have changed,” said Heroux. “The Linpack program performs compute-rich algorithms on dense data structures to identify the theoretical maximum speed of a supercomputer. Today’s applications often use sparse data structures, and computations are leaner.”
Those aren’t just commercial big data applications Heroux is talking about, but also more conventional HPC codes whose behavior is more data demanding. He uses the example of modeling pressure differentials in a fluid flow simulation, where choosing a dense matrix implementation would be prohibitive from both a memory and computational perspective. Of course, other more typical big data applications like machine learning, financial analytics, and fraud detection also rely heavily on random data access.
As such, HPCG was devised as an alternate metric to HPL that addresses these newer applications. To accomplish this, the benchmark uses a preconditioned conjugate gradient algorithm, global collective operations, and sparse data structures. As Heroux suggested, it’s the latter that is key to doing what HPL does not do, namely stressing the memory subsystem.
That’s increasingly important since most systems, supercomputers or otherwise, are much more limited in memory performance than compute performance. While it’s been relatively easy to increase raw processor performance via multicore designs, it’s been much more difficult to build memory subsystems to feed those cores adequately. That’s why there’s a memory wall rather than a compute wall.
As a consequence, HPCG numbers for these big supercomputer systems are much more modest compared to HPL results. While a typical supercomputer usually achieves 50 to 90 percent of its peak performance with HPL, those same systems only deliver a few percentage points of peak running HPCG. In fact, there are 181 systems that have achieved a petaflop or more with Linpack, but none have hit the petaflop mark with HPCG. From a big data perspective, we’re still in the terascale era.
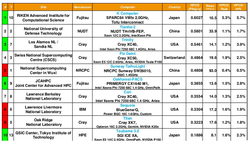
At this point, the top HPCG performer is the K computer at RIKEN, which achieves 602.7 teraflops on the benchmark, representing 5.4 percent of the system’s peak performance. While that percentage might seem low, it’s one of the better yields on the list. In fact, only the NEC vector machines, with their blazing fast memory, are more efficient at extracting HPCG performance, averaging more than 10 percent of peak. By contrast, the top Linpack-ranked Sunway TaihuLight delivers just 480.8 HPCG teraflops, or 0.5 percent of peak. The following table shows the top ten HPCG system, along with their Linpack numbers (Rmax), as of November 2017.
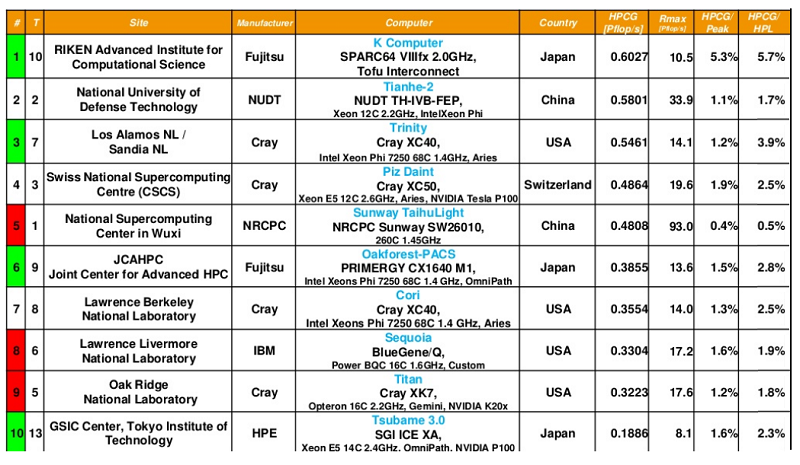 Source: TOP500.org
Source: TOP500.org
Of the 115 systems on the HPCG list, only about half are powerful enough, Linpack-wise, to have earned a TOP500 spot. Nevertheless, these systems are well represented by the major supercomputing powers, with the US, Japan, and China being particularly prominent. Most of these machines are installed at government-backed supercomputing centers and universities, but there are a few commercial machines sprinkled through the list as well. These include Pangea (TOTAL, France) and HPC2 (Eni, Italy), two HPC systems tasked to support oil & gas exploration and production, and Aquarius, a system for an unnamed IT service provider in Germany. System number 115 is HPE’s Spaceborne Computer deployed at the International Space Station. You can peruse the full list here.
As HPC vendors and users get more serious about scaling the memory wall, HPCG might be just the metric to focus attention on the architectural challenges of these systems. Certainly, the increasing use of data-intensive applications of all stripes is creating a demand for such machinery. And just as HPL created a competitive environment for compute-intensive supercomputing, HPCG might do the same in the era of big data.