
July 10, 2017
By: Michael Feldman
Japanese computer-maker Fujitsu is developing an AI-specific microprocessor called the Deep Learning Unit (DLU). The company’s goal is to produce a chip that delivers 10 times better performance per watt than the competition.

Source: Fujitsu
Although the DLU has been in the works since at least 2015, Fujitsu hasn’t talked much about its design. However, last month at ISC 2017, Takumi Maruyama delivered an update on Fujitsu’s HPC and AI efforts, and offered a fairly deep dive into the inner workings of its upcoming deep learning chip. Maruyama, who is the senior director of Fujitsu’s AI Platform Division, has been involved in SPARC processor development since 1993 and is currently working on the DLU project.
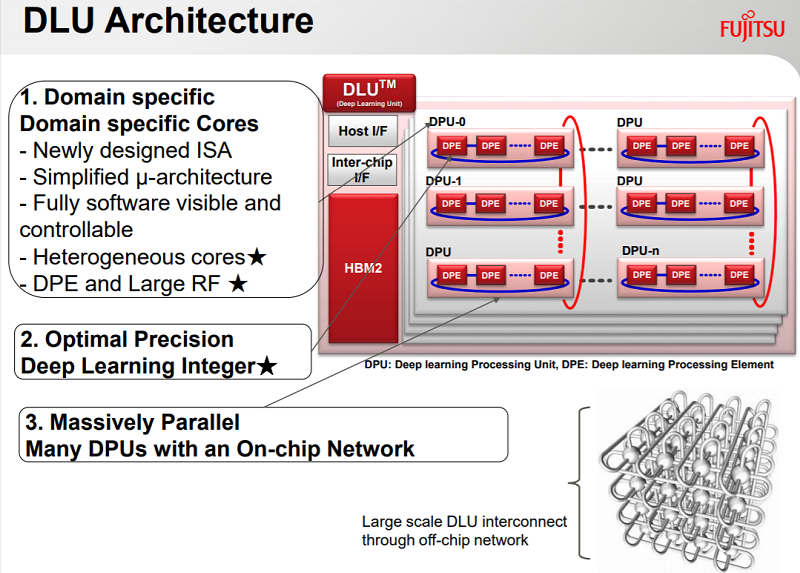
According to Maruyama, like many of the other processors built for deep learning, the DLU relies heavily on lower precision math to optimize both performance and energy efficiency for processing neural networks. Specifically, the chip natively supports FP32, FP16, INT16, and INT8 data types. Fujitsu has demonstrated that lower precision (16-bit and 8-bit) integer formats can be used to good effect on at least some deep learning applications, without a serious loss of accuracy. The idea would be to develop software that could generalize that capability across a wide array of deep learning applications.
At the highest level, the chip is comprised of some number of Deep Learning Processing Units (DPUs), connected with one other through a high-performance fabric. It’s probably useful to think of these DPUs as deep learning cores. A separate master core manages execution on the DPUs and negotiates memory access between the DPUs and an on-chip memory controller.
Source: Fujitsu
Each DPU itself is comprised of 16 deep learning processing elements (DPEs), which is where the actual number crunching takes place. Digging still deeper, each DPE is made up of eight SIMD execution units, along with a very large register file (RF). Unlike a cache, the RF is under full software control.
The DLU package will contain some amount of second-generation high bandwidth memory (HBM2), which will feed data to the processor at high speeds. The package will also include an interface for connecting to other DLUs via the Tofu interconnect (or something similar). Using this off-chip network, Fujitsu envisions very large systems being built, the idea being to create a scalable platform for even the largest and most complex deep learning problems.
The first DLU is scheduled to be available sometime in FY2018, and will be offered as a coprocessor, with a host CPU to drive it. Starting with the next generation of the technology, Fujitsu plans to embed the DPU in a host CPU of some sort. No timeline was offered for this second-generation product.
The company’s ultimate plan is to establish a DLU line in parallel with its array of general-purpose SPARC processors. Like all chipmakers, Fujitsu realizes that AI/machine learning is going to dominate the application space in the not-too-distant future, and those companies that fail to adapt to that reality will be marginalized.
At this point though, there is no consensus if these applications will be primarily running on domain-specific silicon, like DPUs, or more general-purpose architectures like CPUs, GPU, and FPGAs. Currently, NVIDIA, with its heavily AI-tweaked GPUs, dominates the market. But in a fast-moving space like this, things could change rather quickly.
Intel is planning to go to market with its “Lake Crest” processor, which is being built specifically for deep learning codes. Meanwhile, AMD is prepping its new Radeon Instinct GPUs for this same application set. Then there are upstarts like Graphcore, which is looking to outrun them all with its Intelligent Processing Unit (IPU). Like the DLU, the Intel, AMD, and Graphcore products are scheduled to be released into the wild over the next 6 to 12 months.
The challenge for Fujitsu and the other challengers is that NVIDIA has developed a rather formidable lead in deep learning software support and tools for its GPUs. The number of software frameworks for processing neural networks is long and growing, and NVIDIA supports just about every one of them. Any viable contender in this market should support at least the major ones: TensorFlow, Caffe, Microsoft CNTK, Theano, MXNet, and Torch. Tools to help developers build applications around these are also required.
The good news is that while a lot of deep learning software has already been written, it’s a drop in the bucket relative to what will be developed over the next several years. That means there is plenty of room for new entrants. And with deep-pocketed companies like Fujitsu and others jumping into the silicon fray, the space is bound to get even more interesting.