March 26, 2018
By: Michael Feldman
Using the newly developed SNAP Machine Learning (SNAP ML) framework and Power9/V100 GPU servers, IBM researchers were able to blow past Google’s previous benchmark for training an online advertising application.
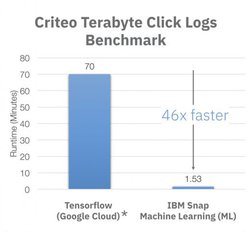
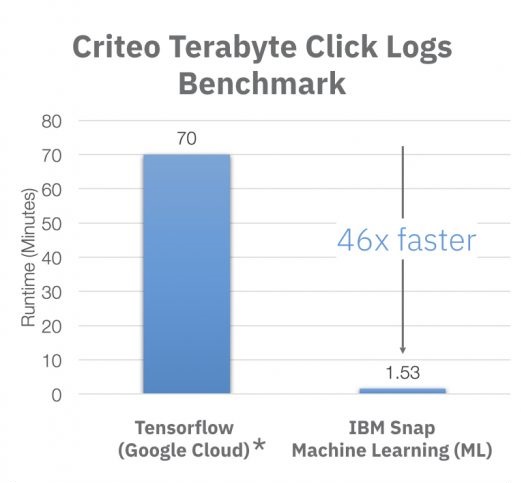 The application, a logistic regression classifier, uses an online advertising click log dataset compiled by Criteo Labs to predict the chances a user will click through to an ad under a given scenario. The dataset contains 4.2 billion training examples, each of which records whether or not a user has clicked on an online advertisement under a variety of conditions. Google had previously trained the application with this same dataset, using TensorFlow and CPU-powered cloud servers, achieving a 70-minute turnaround time – the high-water mark until last week. IBM was able achieve the same accuracy on the model with just 91.5 seconds of training, thanks to its SNAP ML framework and four AC922 servers. Each of those servers was equipped with two Power9 CPUs and four NVIDIA V100 GPUs.
The application, a logistic regression classifier, uses an online advertising click log dataset compiled by Criteo Labs to predict the chances a user will click through to an ad under a given scenario. The dataset contains 4.2 billion training examples, each of which records whether or not a user has clicked on an online advertisement under a variety of conditions. Google had previously trained the application with this same dataset, using TensorFlow and CPU-powered cloud servers, achieving a 70-minute turnaround time – the high-water mark until last week. IBM was able achieve the same accuracy on the model with just 91.5 seconds of training, thanks to its SNAP ML framework and four AC922 servers. Each of those servers was equipped with two Power9 CPUs and four NVIDIA V100 GPUs.
One might attribute the 46x speedup for the IBM run on the use of the GPUs, but that’s only a part of the story. Google explicitly did not use GPUs for their benchmark since they found that using them did not result in large improvement in performance for this training application. That’s because the dataset is so large that a lot of time is spent shuffling data in and out of the local GPU memory, so much in fact that the processors are idled for long periods, waiting for memory copies to complete. For Google, the GPUs just weren’t worth the extra trouble.
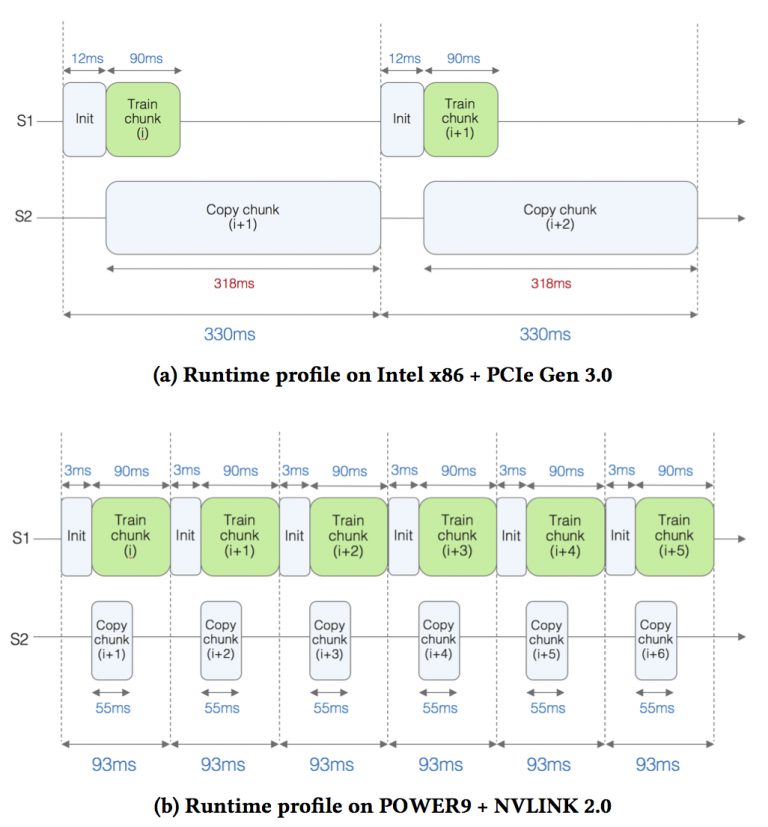
IBM gets around this in two ways. First, the SNAP ML code is designed to optimize data locality in the GPU memory to avoid data transfer overheads as much as possible. This makes it easier to slice up these large datasets into bite-sized chunks for the GPUs to work on. Second, by using the Power9 CPU and its ability to use NVLink as the commication link to the V100, memory copies to and from the GPU can be performed about six times faster than over PCIe.
The result of this software/hardware approach is that the time taken to execute the training computation pieces is now longer than the time taken for data transfers, which means data copying and computation can be overlapped without processor stalls. (See the figure below for the specifics.). IBM says the total training time on the Power9-V100 combo is about 3.5 times faster compared to a Xeon-V100 server without the NVLink boost, i.e., with the GPU attached via PCIe.
Source: IBM Research
According to IBM, being able to deal with challenging data environments also makes SNAP ML a good candidate for real-time or near-real-time applications where the model must be trained on-the-fly from streaming data. The framework is also supposed to be good at ensemble learning, where multiple solvers are used to form a consensus on a given problem.
Also, besides logistic regression problems like this click-rate application, SNAP ML is also specifically optimized for linear regression and support vector machines types of problems. While these three might sound somewhat obscure for non-mathematicians, they encompass a wide array of useful real-world applications, including things like detecting credit card fraud, determining if credit should be extended customers, forecasting sales, and predicting a stock's volatility.
The SNAP ML library, which has been two years in the making, is still in the lab at IBM Research. The plan is to make it available to customers on a trial basis later this year as part of a PowerAI preview. IBM is actively looking for interested clients.