
Aug. 23, 2017
By: Michael Feldman
At the Hot Chips conference this week, Microsoft has revealed its latest deep learning acceleration platform, known as Project Brainwave, which the company claims can deliver “real-time AI.” The new platform uses Intel's latest Stratix 10 FPGAs.
 Project Brainwave board. Source: Microsoft
Project Brainwave board. Source: Microsoft
Stratix 10 is Intel’s newest FPGA offering and is built using the chipmakers 14nm process technology. Microsoft has been an enthusiastic backer of FPGAs for AI work and other datacenter applications, and has deployed them across its Azure cloud. Today, those devices are powering everything from Bing searches and Skype language translations, to cloud network acceleration.
For those original Azure deployments, Microsoft used the Stratix V and Arria 10 FPGAs, products which Intel inherited from Altera when it purchased the company back in 2015. The new Stratix 10 is still essentially an Altera design, but is being manufactured on Intel’s advanced 14 nm Tri-Gate process, which the company claims will provide twice the performance over previous generation FPGAs.
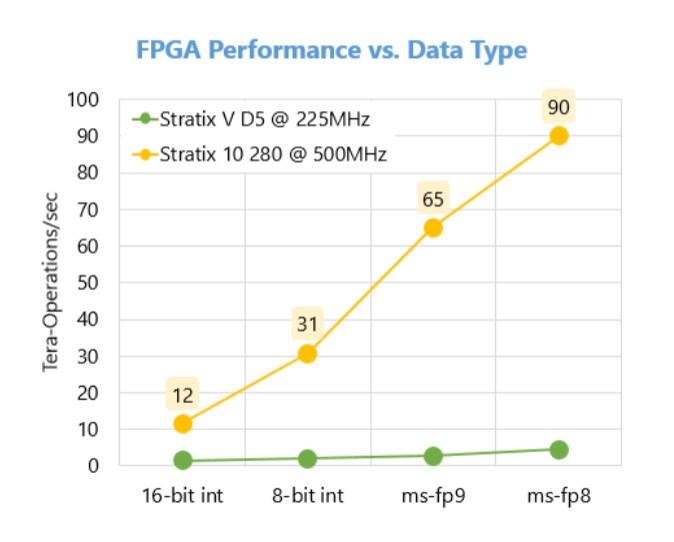
In the Project Brainwave presentation at Hot Chips, delivered by Microsoft’s Eric Chung and Jeremy Fowers, a chart was presented on how much more capability the Stratix 10 FPGA deliver compared to the older Stratix V, at least for these low-precision inferencing operations for deep neural networks. Performance on the early Stratix 10 silicon ranged from 12 and 31 teraops for 16-bit and 8-bit integers, respectively, all the way up 90 teraflops for Microsoft’s custom 8-bit floating point (ms-fp8). Corresponding values for the Stratix V FPGA were 1.4 and 2.0 teraops, and 4.5 teraflops. According to Microsoft, they are able to retain very respectable accuracy using their 8-bit floating point format across a range of deep learning models.
For what it’s worth, NVIDIA latest Volta-class V100 GPU delivers 120 teraflops of mixed 16/32-bit floating point math, while Wave Computing's Dataflow Processing Unit is estimated to attain 180 teraops of undetermined precision. Google, meanwhile, says its second-generation TPU ASIC can provide 180 teraflops, also of undetermined precision.
 Source: Microsoft
Source: Microsoft
Hardware specs aside, the AI magic behind Project Brainwave is accomplished by loading a “soft” deep neural network processing unit (DPU) onto the FPGA. Microsoft maintains this is a more flexible approach than using a custom ASIC, as Google has done with its TPU, or others like Graphcore and Wave Computing have developed. They think the FPGA approach is especially advantageous for inferencing already trained neural networks, which demands the kind of latency you need for real-time responses.
In this case, the quick response time is the result of being able to optimize neural network inferencing with a combination custom-synthesized logic on the reconfigurable elements and tapping into the hardened DSP blocks, as well as taking advantage of on-chip memory for data transfers. Latencies are further reduced since all this processing can take place independently of the server’s CPU host.
In a blog posted by Doug Burger, a lead Microsoft engineer on Azure’s configurable cloud architecture, he claims the Project Brainwave platform can “achieve performance comparable to – or greater than – many of these hard-coded DPU chips but are delivering the promised performance today.” To support that, he described a deep learning inferencing run in which they were able to demonstrate 39.5 teraflops on a very large GRU (gated recurrent unit) neural network. At that rate, Burger said each inferencing request was delivered in less than a millisecond.
In general, Microsoft wanted to reduce latencies as much as possible, while supporting different types of deep learning models, including memory-intensive ones, like LSTM (Long Short Term Memory) networks. Explaining the design approach, Burger writes:
We architected this system to show high actual performance across a wide range of complex models, with batch-free execution. Companies and researchers building DNN accelerators often show performance demos using convolutional neural networks (CNNs). Since CNNs are so compute intensive, it is comparatively simple to achieve high performance numbers. Those results are often not representative of performance on more complex models from other domains, such as LSTMs or GRUs for natural language processing.
Since their neural network compiler generates a graph-based intermediate representation for trained models, Microsoft says they are able to support a wide range of deep learning frameworks. Currently, the FPGA implementations they have developed for the platform are restricted to the Microsoft Cognitive Toolkit and Google’s Tensorflow. The plan is to support many more of the most popular frameworks.
Initially, the platform will be used to support the AI capabilities in Microsoft services like Bing and Skype. But ultimately, they want to make it available via Azure’s public cloud, so customers can run their own deep learning applications on it. The company has not specified a timeline for that rollout, only saying that we can expect this capability in “the near future.” In the meantime, Microsoft will be tuning the platform to further boost performance.