Nov. 28, 2016
By: Michael Feldman
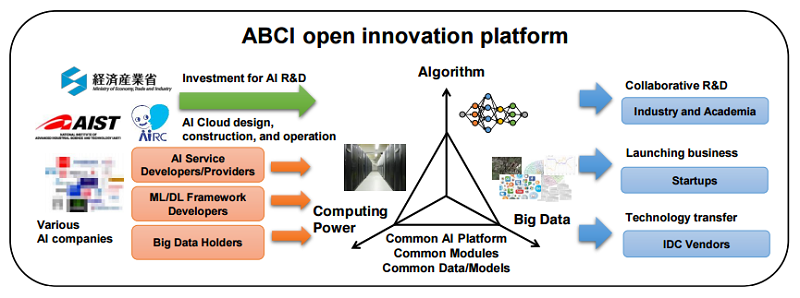
The Tokyo-based National Institute of Advanced Industrial Science and Technology (AIST) is taking bids for a new supercomputer that will deliver more than 130 half precision petaflops when completed in late 2017. The system, known as the AI Bridging Cloud Infrastructure (ABCI), is mainly being built for artificial intelligence developers and providers, and will be made available as a cloud resource to researchers and commercial organizations.
 Source: AIST
Source: AIST
The ostensible goal is to “rapidly accelerate the deployment of AI into real businesses and society” – that according to a one-page fact sheet presented at the recent SC16 conference in Salt Lake City. But as is apparent from that document, the supercomputer will also support more traditional users of HPC and advanced analytics applications.
The cloud aspect of the system will make it possible for outside entities to use its resources. According to a Reuters report, Japanese corporations can employ the supercomputer for a fee in the same manner as renting cycles on public clouds like Amazon Web Services or Microsoft Azure. Operating a government-funded supercomputer as a pay-as-you-go utility has proved to be a little tricky in practice, but that hasn’t prevented others from trying.
The overarching objective here is to jump-starting the AI industry in Japan. The US and China are already well-established in this area, with Google, Microsoft, Baidu and other large hyperscale companies leading the way. But there will be plenty of opportunity for more specialized companies to establish themselves locally as the demand for commercial AI services expands on a regional level in areas like transportation, electronic design, financial services, government programs, healthcare, and retail.
Bidding on the system is underway and is scheduled to close on December 8th. The solicitation calls for a “open hardware and software architecture with accelerator support based on commodity devices.” The system will include the expected complement of high performance interconnects, memory and storage, the latter being in the multi-petabyte range. The Japanese government has allocated 19.5 billion yen ($173 million) to develop and deploy ABCI.
Like all large-scale Japanese supercomputers these days, there will be a concerted effort to make ABCI highly energy-efficient. In this case, the system will use an ambient warm water cooling capability, which obviates the need for expensive chillers. ABCI will also employ a large Lithium-ion battery storage system. It’s not clear if the battery capability is there for backup or to provide power in conjunction with some intermittent energy source.
According to the ACBI fact sheet, stated goal is to run the system on less than 3 MW of power, which would work out to about 43 gigaflops/watt. But since those are single half precision (16-bit) flops, that’s more like 11 gigaflops/watt when we’re talking double precision Green500 numbers (and probably a good deal less than that considering those rankings are based on Linpack flops, not peak flops). Nevertheless, that’s still a very green machine. The current leader in energy efficiency on the Green500 list is NVIDIA’s DGX SATURNV supercomputer with a mark of 9.5 gigaflops/watt.
The call for commodity accelerators narrows the choices of componentry substantially. The inside favorite is NVIDIA with its AI-tweaked GPUs, like the latest P100 parts. (The P100, by the way, is the basis of the previously mentioned DGX SATURNV system.) By the end of 2017, NVIDIA might have the next-generation Volta GPUs in production, but the timing could be a little tight for the ABCI deployment. Intel will likely have its AI-flavored “Knights Mill” Xeon Phi in production in that timeframe as well, so that’s another viable option. The recently announced Intel “Lake Crest” accelerator is an additional possibility, although that one is custom-built for AI applications, so would not fulfill the more general-purpose HPC and analytics functions of the system. It’s possible that ABCI will be equipped with some combination of NVIDIA and Intel accelerators, giving users the option to explore the various capabilities that they present.
System contractors could be almost anyone, although if the NVIDIA is tapped as the accelerator provider, IBM would be a logical choice as the system provider, since it is the only OEM that supports the NVLink capability natively on the CPU side (with Power8 and Power9). NVlink is NVIDIA’s custom interconnect that greatly speeds data transfers between GPUs and between the GPUs and the host processor. Cray, Hewlett Packard Enterprise (HPE), and Fujitsu are other reasonable options as system providers, and even NEC or Hitachi could get a piece of the action. Intel could also act as the principle contractor, as it did with its 180-petaflop Aurora system for the US Department of Energy, which is scheduled to be installed in the same general timeframe. Whoever gets the work will enjoy the prestige of building the world’s first leading-edge supercomputer aimed at the AI application space.
To the extent that AIST make the platform available for other users, it could also be an opportunity for machine learning enthusiasts to explore larger problems and train much more complex neural networks. Scalability is one of the more persistent application bottlenecks in the AI space, and this machine would provide the platform to explore networks spread across hundreds or even thousands of nodes. In that sense, it could become a model for subsequent supercomputers that carry this application space into the exascale era.