
Aug. 8, 2017
By: Michael Feldman
This week IBM demonstrated software that was able to significantly boost the speed of training deep neural networks, while improving the accuracy of those networks. The software achieved this by dramatically increasing the scalability of these training applications across large number of GPUs.
 Source: IBM Research
Source: IBM Research
In a blog posted by IBM Fellow Hillery Hunter, director of the Accelerated Cognitive Infrastructure group at IBM Research, she outlined the motivation for the work:
“For our part, my team in IBM Research has been focused on reducing these training times for large models with large data sets. Our objective is to reduce the wait-time associated with deep learning training from days or hours to minutes or seconds, and enable improved accuracy of these AI models. To achieve this, we are tackling grand-challenge scale issues in distributing deep learning across large numbers of servers and GPUs.”
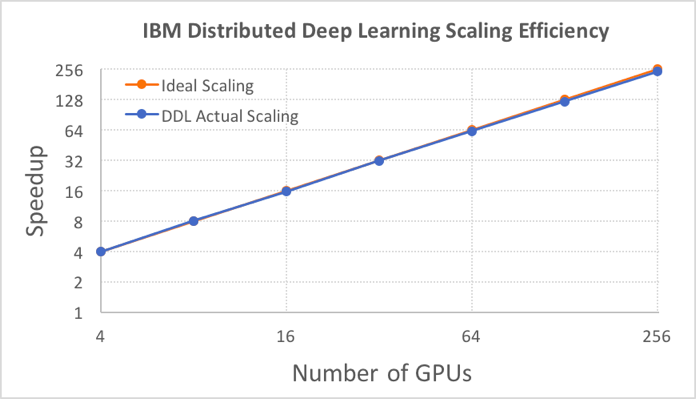
The technology they developed to accomplish this, encapsulated in their Distributed Deep Learning (DDL) software, delivered a record 95 percent scaling efficiency across 256 NVIDIA Tesla P100 GPUs using the Caffe deep learning framework for an image recognition application. That exceeds the previous high-water mark of 89 percent efficiency achieved by Facebook for training a similar network with those same GPUs on Caffe2.
 Source: IBM Research
Source: IBM Research
The quality of the training was also improved by the DDL software, which delivered an image recognition accuracy of 33.8 percent for a network trained with a ResNet-101 model on a 7.5-million image dataset (ImageNet-22k). The previous best result of 29.8 percent accuracy was achieved by Microsoft in 2014. But in the case of the IBM training, its level of accuracy was achieved in just 7 hours of training, while the Microsoft run took 10 days.
It should be noted that the Microsoft training was executed on a 120-node HP Proliant cluster, powered by 240 Intel Xeon E5-2450L CPUs, while the IBM training was executed on a 64-node Power8 cluster (Power Systems S822LC for HPC), equipped with 256 NVIDIA P100 GPUs. Inasmuch as those GPUs represent more than two petaflops of single precision floating point performance, the IBM system is about two orders of magnitude more powerful than the commodity cluster used by Microsoft.
That doesn’t negate the importance of the IBM achievement. As was pointed out by Hunter in her blog, scaling a deep learning problem across more GPUs is made much more difficult as these processors get faster, since communication between them and the rest of the system struggles to keep pace as the computational power of the graphics chips increase. She describes the problem as follows:
“[A]s GPUs get much faster, they learn much faster, and they have to share their learning with all of the other GPUs at a rate that isn’t possible with conventional software. This puts stress on the system network and is a tough technical problem. Basically, smarter and faster learners (the GPUs) need a better means of communicating, or they get out of sync and spend the majority of time waiting for each other’s results. So, you get no speedup–and potentially even degraded performance–from using more, faster-learning GPUs.”
 IBM Fellow Hillery Hunter. Source IBM
IBM Fellow Hillery Hunter. Source IBM
At about 10 single precision teraflops per GPU, the NVIDIA P100 is one of the fastest GPUs available today. The NVIDIA V100 GPUs, which are just entering the market now, will offer 120 teraflops of mixed single/half precision performance, further challenging the ability of these deep learning applications to scale efficiently.
The IBM software is able to overcome the compute/communication imbalance to a great extent by employing a multi-dimensional ring algorithm. This allows communication to be optimized based on “the bandwidth of each network link, the network topology, and the latency for each phase.” This is accomplished by adjusting the number of dimensions and the size of each one. For server hardware with different types of communication links, the software is able to adjust its behavior to take advantage of the fastest links in order to avoid bottlenecks in the slower ones.
Even though this is still a research effort, the DDL software is going to be available to customers on a trial basis as part of IBM’s PowerAI, the company’s deep learning software suite aimed at enterprise users. DDL is available today in version 4 of PowerAI, and according to IBM, it contains implementations at various stages of development, for Caffe, Tensorflow, and Torch.
An API has been provided for developers to tap into DDL’s core functions. The current implementation is based on MPI – IBM’s own Spectrum MPI, to be specific – which provides optimizations for the company’s Power/InfiniBand-based clusters. IBM says you can also use DDL without MPI underneath if desired, but presumably your performance will vary accordingly. IBM is hoping that third-party developers will start using this new capability and demonstrate its advantages across a wider array of deep learning applications.