July 13, 2017
By: Michael Feldman
One of the more significant architectural advancements in Intel’s new Xeon scalable processor, aka Skylake, is the use of a mesh interconnect that link cores and other on-chip componentry.
In a blog posted last month by Intel Engineer Akhilesh Kumar, he described the need to design the right kind of interconnect to link up the various parts on the processor die. “The task of adding more cores and interconnecting them to create a multi-core data center processor may sound simple, but the interconnects between CPU cores, memory hierarchy, and I/O subsystems provide critical pathways among these subsystems necessitating thoughtful architecture,” he wrote.
In the case of the new Xeon processors, the mesh is a 2D interconnect that links cores, shared cache, memory controllers, and I/O controllers on the chip. The mesh is arranged in rows and columns, with switches at the intersections so that data may be directed to the shortest path. The schematic below shows an example of the mesh with a 22-core Xeon die.
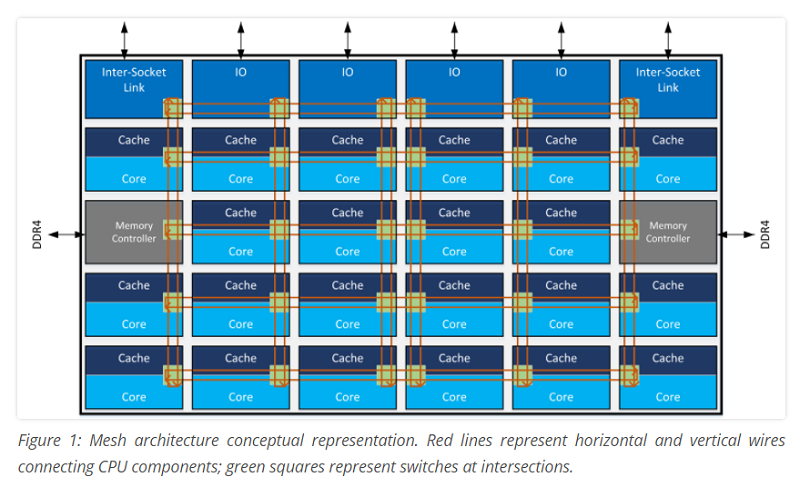 Source: Intel
Source: Intel
Prior to the Skylake product, Intel employed a ring interconnect to glue these pieces together. With a ring setup, communication bandwidth, and especially latency, can become a problem as more cores and interfaces are added. That’s because when there are too many endpoints on the interconnect, data must often travel across many intermediate hops to get from its source to its destination. With up to 28 cores, 48 PCIe lanes, and six memory channel interfaces per processor, the new chips became too complex for a simple ring topology.
Since a mesh offers a row/column topology, data traversal across the chip becomes less arduous, which theoretically improves performance. It’s a bit of a tradeoff, inasmuch as you have to devote more chip real estate and power to the mesh’s wires and switches. But as processors evolve from multicore into manycore platforms, such a development is unavoidable. It’s notable that Intel’s Xeon Phi products, which have dozens of cores, use a similar sort of mesh, although in this case the cores are arranged in dual-core tiles, which cuts the number of switches in half.
Another advantage of the mesh is that it enables last level L3 cache that is spread across the cores to be accessed with lower latency, which, as Kumar puts it, “allows software to treat the distributed cache banks as one large unified last level cache.” As a result, applications behave more consistently and developers don’t have to worry about variable latencies as their applications are scaled across more cores. The same goes for memory and I/O latencies, since these controller interfaces are also included in the on-chip mesh.
Presumably Intel will be able to leverage the mesh technology across subsequent generations of the Xeon processor, even as core counts increase. Theoretically, another interconnect design will be needed at some point, since even a 2D topology will become constricting if processors start sprouting hundreds of cores. But that day is probably far in the future.