
May 1, 2018
By: Michael Feldman
Google has announced it is offering NVIDIA Tesla V100 GPUs for its HPC and machine learning cloud customers. But how will the company square this with its TPU cloud offering?
Google's deployment of the V100 follows that of Amazon, IBM, and Microsoft, who have offered this GPU in their respective clouds for some time. Amazon was the first provider to make it available to cloud customers, when it rolled out its V100 instances in October 2017. The V100 is currently NVIDIA’s most advanced accelerator, offering 7.5 teraflops of double precision performance for HPC and 125 teraflops of tensor mixed precision performance for machine learning.
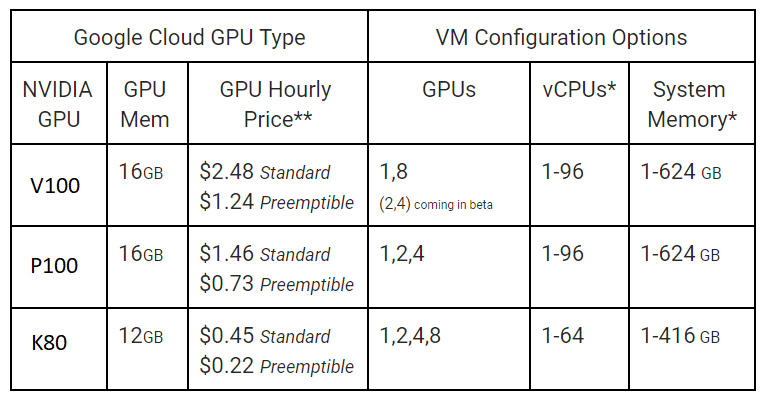
According to a blog posted on Monday by NVIDIA product managers Chris Kleban and Ari Liberman, the V100 solution will initially be offered in beta. Customers will be able put up to eight of the GPUs, along with 96 vCPUs and 624 GB of memory in a single virtual machine. With that configuration, a user can tap into 60 teraflops of double precision or one petaflop of tensor performance. Kleban and Liberman write that HPC and deep learning workloads will realize a 40 percent performance boost with these latest GPUs.
In conjunction with the V100 launch, Google is also moving its Tesla P100 GPU cloud offering from beta to general availability. This one has almost the same configuration as the V100 offering, with up to 96 vCPUs and 624 GB of high bandwidth memory, but with a maximum GPU count of four. Given the lower relative performance of the P100 – 5.3 teraflops for HPC and 21.2 teraflops for machine learning – the P100 is a good deal less powerful than its younger sibling. The older K80 GPU, which Google has offered for some time and continues to support, is even less powerful than the P100. The company has priced them all accordingly, as can be seen from the table below.
 Source: NVIDIA
Source: NVIDIA
Currently, the V100s will be available to Google customers in its Western and Central US regions, as well as parts of Western Europe. The P100 has a wider distribution and is available in Google’s Western, Central and Eastern US regions, Eastern Asia, and Western Europe. The price table above applies only to US regions.
Google is ostensibly aiming the V100 and P100 at HPC and machine learning customers. In the blog announcement, two customers are mentioned: LeadStage, which is using both the V100 and P100 for optical character recognition on handwritten documents, and Chaos Group, which is employing the V100s for V-Ray Cloud rendering.
As we’ve reported before previously, Google has a divergent strategy with regard to machine learning in the cloud. Back in February, the company launched its Tensor Processing Units (TPUs) into its public cloud. The TPUs were custom-designed specifically for machine learning workloads and up until February had only been used internally by Google for its own applications like web search and language translation. By offering the TPUs to the general public, the web giant seemed to be probing customer interest in an alternative machine learning platform.
Google is renting its TPU board at a price of $6.50 per hour. For that you get 180 machine learning teraflops and a minimal software stack based on the TensorFlow framework. Now for $2.48 per hour, you can get a V100, which delivers 125 teraflops and comes with a much more extensive ecosystem of libraries and tools. It should be noted that the TPU boards, which contains four TPU chips, comes with 64 GB of high bandwidth memory (16 GB per chip), versus 16 GB on a single V100 device.
Given all that, the V100 would seem to be the better deal. However, a few months ago Elmar Haußmann, cofounder and CTO of RiseML, compared the performance of four V100s in AWS against Google’s four-TPU cloud board, running an image classification training application (ResNet-50 on ImageNet). The idea was to match up both processor count and memory capacity. He found that the application performance for the TPU board and four-V100 setup was very similar, with the V100 only showing an advantage with smaller batch sizes. Moreover, Haußmann found that the TPU’s performance per dollar was significantly better than the V100 based on the AWS pricing. Since Google's standard rate for its V100 for only about a third of the cost of its TPU board, Google’s custom silicon would still come out on top in price-performance – at least for this particular application. That said, the preemptible pricing for the V100 is only about 20 percent that of the TPU, which would give the NVIDIA hardware the price edge.
For other machine learning applications, or perhaps even for ResNet 50 if a different software stack was employed, the V100 might be able to demonstrate a much clearer advantage. That would have to be determined on a case-by-case basis. Of course, if a customer is already invested in CUDA and NVIDIA machine learning libraries, the choice is pretty obvious. And certainly, for more conventional HPC applications, the V100 or any of the other GPUs would be the way to go, given the unsuitability of the TPU for non-machine learning software.
For the time being, Google is likely resigned to the fact that only its most adventurous customers will opt for the TPU platform. In the longer term though, the web giant would probably like to see this solution become a more standard option for its cloud customers, which would spread the cost of its chip design, production, and software support across a larger user base. In the meantime, Google seems willing to offer a somewhat confusing choice to its customers.