
Feb. 14, 2017
By: Michael Feldman
Exabyte, a materials discovery cloud specialist, has published a study that compares Linpack performance on four of the largest public cloud providers. Although the study’s methodology had some drawbacks, the results suggested that with the right hardware, HPC applications could not only scale well in cloud environments, but could also deliver performance on par with that of conventional supercomputers.
Overall, HPC practitioners have resisted using cloud computing for a variety of reasons, one of the more significant being the lack of performant hardware available in cloud infrastructure. Cluster network performance, in particular, has been found wanting in generic clouds, since conventional Ethernet, both GigE and 10GigE, do not generally have the bandwidth and latency characteristics to keep up with MPI applications running on high core-count nodes. As we’ll see in a moment, it was the network that seemed to matter most in terms of scalability for these cloud environments.
The Exabyte study used high performance Linpack (HPL) as the benchmark metric, measuring its performance on four of the most widely used public clouds in the industry: Amazon Web Service (AWS), Microsoft Azure, IBM SoftLayer, and Rackspace. (Not coincidentally Exabyte, a cloud service provider for materials design, device simulations, and computational chemistry, employs AWS, Azure, SoftLayer and Rackspace as the infrastructure of choice for its customers.) Linpack was measured on specific instances of these clouds to determine benchmark performance across different cluster sizes and its efficiency in scaling from 1 to 32 nodes. The results were compared to those on Edison, a 2.5 petaflop (peak) NERSC supercomputer built by Cray. It currently occupies the number 60 spot on the TOP500 rankings.
To keep the benchmark results on as level a playing field as possible, it looks like the Exabyte team tried to use the same processor technology across systems, in this case, Intel Xeon processors of the Haswell or Ivy Bridge generation. However, the specific hardware profile – clock speed, core count, and RAM capacity -- varied quite a bit across the different environments. As it turns out though, the system network was the largest variable across the platforms. The table below shows the node specification for each environment.
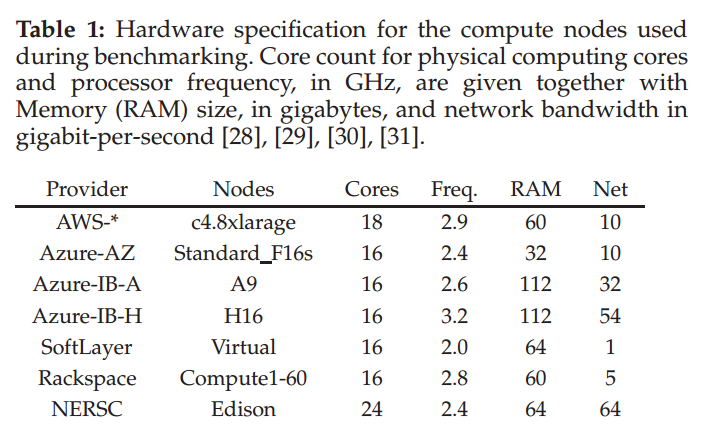 Source: Exabyte Inc.
Source: Exabyte Inc.
As might be expected, Edison was able to deliver very good results, with a respectable 27-fold speedup as the Linpack run progressed from 1 to 32 nodes, at which point 10.44 teraflops of performance was achieved. That represents decent scalability and is probably typical of a system with a high-performance interconnect, in this case Cray’s Aries network. Note that Edison had the highest core count per node (48), but one of the slower processor clocks (2.4 GHz) of the environments tested.
The AWS cloud test used the c4.8xlarage instance, but was measured in three different ways: one with hyperthreading enabled, one with hyperthreading disabled, and one with hyperthreading disabled and with the node placements optimized to minimize network latency and maximize bandwidth. The results didn’t vary all that much between the three with maximum Linpack performance of 10.74 being recorded for the 32-node setup with hyperthreading disabled and optimal node placement. However the speedup achieved for 32 nodes was just a little over 17 times that of a single node.
The Rackspace cloud instance didn’t do nearly as well in the performance department, achieving only 3.04 teraflops on the 32-node setup. Even with just a single node, its performance was much worse than that of the AWS case, despite having more cores, a similar clock frequency, and an identical memory capacity per node. Rackspace did, however, deliver a better than an 18-fold speed as it progressed from 1 to 32 nodes -- slightly better than that of Amazon. That superior speedup is not immediately explainable since AWS instance provides more than twice the bandwidth of the Rackspace setup. It’s conceivable the latter’s network latency is somewhat lower than that of AWS.
IBM SoftLayer fared even worse, delivering just 2.46 Linpack teraflops at 32 nodes and a speedup of just over 4 times that of a single node. No doubt the relatively slow processor clock (2.0 GHz) and slow network speed (1 gigabit/sec) had a lot to do with its poor performance.
Micrsoft’s Azure cloud offered the most interesting results. Here the Exabyte team decided to test three instances F16s, A9, and H16. The latter two instances were equipped with InfiniBand, the only platforms in the study where this was the case. The A9 instance provided 32 gigabits/sec and the H16 instance provided 54 gigabits/sec – nearly as fast as the 64 gigabits/sec of the Aries interconnect on Edison.
Not surprisingly, the A9 and H16 exhibited superior scalability for Linpack, specifically, more than a 28-fold speedup on 32 nodes compared to a single node. That’s slightly better than the 27x speedup Edison achieved. In the performance area, the H16 instance really shined, delivering 17.26 Linpack teraflops in the 32-node configuration. That’s much higher than any of the other environments tested, including the Edison supercomputer. It’s probably no coincidence that the H16, which is specifically designed for HPC work, was equipped with the fastest processor of the bunch at 3.2 GHz. Both the A9 and H16 instances also had significantly more memory per node than the other environments.
One of the unfortunate aspects of the Edison measurement is that they enabled hyperthreading for the Linpack runs, something Intel explicitly says not to do if you want to maximize performance on this benchmark. With the exception of one of the AWS tests, none of the others ran the benchmark with hyperthreading enabled.
In fact, the poor Linpack yield on Edison, at just 36 percent of peak in the 32-node test run, suggests the benchmark was not devised very well for that system. The actual TOP500 run across the entire machine achieved a Linpack yield of more than 64 percent of peak, which is fairly typically of an HPC cluster with a high-performance network. The Azure H16 in this test had a 67 percent Linpack yield.
There’s also no way to tell if other hardware variations – things like cache size, memory performance, etc. -- could have affected the results across the different cloud instances. In addition, it was unclear if the benchmark implementations were optimized for the particular environments tested. Teams working on a TOP500 submission will often devote weeks to tweaking a Linpack implementation to maximize performance on a particular system.
It would have been interesting to see Linpack results on other InfiniBand-equipped clouds. In 2014, an InfiniBand option was added to SoftLayer, but the current website doesn’t make any mention of such a capability. However, Penguin Computing On Demand, Nimbix, and ProfitBricks all have InfiniBand networks for their purpose-built HPC clouds. Comparing these to the Azure H16 instance could have been instructive. Even more interesting would be to see other HPC benchmarks, like the HPCG metric or specific application kernels tested across these platforms.
Of course, what would be ideal would be some sort of cloud computing tracker that could determine the speed and cost of executing your code on a given cloud platform at any particular time. That’s apt to require a fair amount of AI, not to mention a lot more transparency by cloud providers on how their hardware and software operates underneath the covers. Well, maybe someday...