
June 27, 2016
By: Michael Feldman
Multiple outlets are reporting that Oak Ridge National Lab’s (ORNL) Summit supercomputer, one of the three pre-exascale systems being developed for the Department of Energy under its CORAL program, will hit 200 petaflops when it becomes operational in two years. The implication is that the US is responding to the announcement of TaihuLight, the new Chinese supercomputer that captured the top spot on the latest TOP500 list. But the storyline here is a lot more nuanced than that.

The news about Summit comes from a Computerworld article that reported ORNL is expecting the system will reach 200 peak petaflops when it is installed in 2018. Previous characterizations of the system had it achieving between 150 to 300 petaflops. But the specific goal of 200 petaflops was established well before last week’s announcement of the 125-petaflop TaihuLight machine.
In a Congressional Budget Request from the DOE dated February 2016, the agency put forth an FY2017 funding request for site preparation for Summit at ORNL, as well as installation and operation of the smaller 8.5-petaflop Theta supercomputer to be deployed at Argonne National Lab this year. In the request, the 200-petaflop figure is called out:
“The OLCF will begin to install cabinets for the new 200pf IBM Power9 heterogeneous supercomputer with NVIDIA Volta GPUs at the end of FY 2017. Installation, testing, early science access and transition to operations for the system, named Summit, are all planned for FY 2018. This upgrade will provide approximately five times the capability of Titan.”
In an internal presentation by the DOE office of Advanced Scientific Computing Research (ASCR) from April 2016, the 200-petaflop goal for Summit appears again, along with the latest information regarding the agency's Cori, Theta, and Aurora supercomputing deployments.
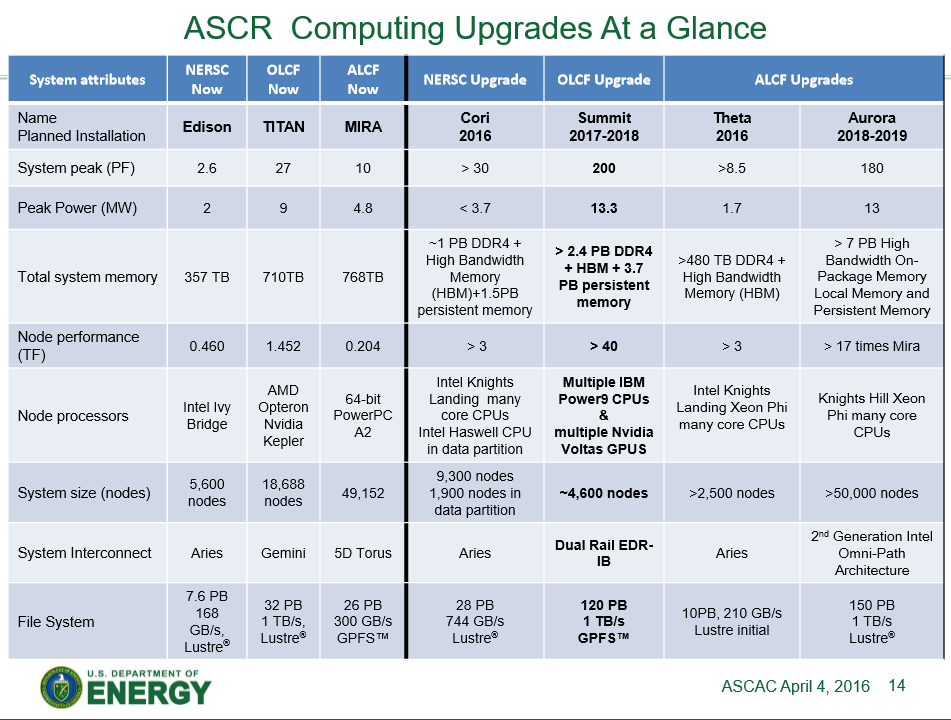
Note that the updated spec for Summit (above) provides a higher node count of ~4600, compared to ~3400 for the original 150-petaflop configuration. The total peak power draw increased accordingly, from 10MW to 13.3MW. TaihuLight, the current top system, uses more than 15MW. Also note that the Aurora system, which is planning to use the next-generation Knights Hill Xeon Phi processors and reach 180 petaflops in 2018-2019, will draw nearly the same amount of power as the Power9/Volta GPU-powered Summit, but will do so with about 10 times as many nodes.
This money for Summit’s and Aurora’s site preparation is not allocated yet, nor is the money for their actual installations, which presumably will be part of the FY18 budget request. So all of this might turn out to be wishful thinking, and given Congress’s recent performance, it surely could. But that’s the plan as it stands today.
Of course, by the time Summit and Aurora are installed, there may be other Chinese systems of similar or even greater performance. Regardless, the DOE’s supercomputing timeline is more methodical than that of its Chinese counterparts, and there does not appear to be any specific effort by US policymakers to catch up to their rivals in the FLOPS department.
That contrasts markedly with what happened in 2002 when Japan’s Earth Simulator opened up a performance gap with the US systems similar to the one we see today with TaihuLight. At that time, the response by the DOE was immediate and spurred the agency to accelerate their supercomputing program significantly.
That doesn’t appear to be happening today. The current emphasis at the DOE’s ASCR office is to field systems that provide application performance commensurate with the underlying system, that is, enable software to efficiently extract the performance from the hardware, and do so at ever-increasing scale. And that’s something that is still a big question mark with the fastest Chinese systems. Here it’s worth noting that the Earth Simulator wasn’t just a FLOPS monster; it was considered one of the most efficient systems of its day from an applications perspective.
On the other hand, the US response is likely to be very different if the Chinese systems manage to close the application gap on their way to exascale. That’s a more difficult task than just developing fast processors and adding more of them to a machine, but given China’s trajectory in supercomputing over the last several years, it is certainly conceivable.